数据结构类型算法
数据结构类型算法
递归函数怎么写?
写递归算法的关键是要明确函数的「定义」是什么,然后相信这个定义,利用这个定义推导最终结果,绝不要跳入递归的细节。
举个例子:
比如说让你计算一棵二叉树共有几个节点:
// 定义:count(root) 返回以 root 为根的树有多少节点
int count(TreeNode root) {
// base case
if (root == null) return 0;
// 自己加上子树的节点数就是整棵树的节点数
return 1 + count(root.left) + count(root.right);
}
递归函数一般分为三部分
递归结束条件,递归语句,实际干活语句
拿上面的递归函数举例子
int count(TreeNode root) {
//结束条件
if (root == null) return 0;
//这里把实际干活代码和递归语句合并了,实际上是这样的
// int a = count (root.left)
// int b = count (root.right)
//相当于实际干活代码是a+b,count(root.left)和count(root.right)就是递归语句
//return a+b;
return 1 + count(root.left) + count(root.right);
}
链表
合并链表

很容易想到的是选择一个链表遍历这个链表将这个链表中的节点一一加入到另一条链表中,但是如果是 [2] [1] 这样的就不好处理
class Solution {
public ListNode mergeTwoLists(ListNode l1, ListNode l2) {
ListNode l,temp;
if(l1 == null) return l2;
while(l2 != null){
temp = l2.next;
l = l1;
while(l.next != null && l2.val >= l.next.val){
l = l.next;}
l2.next = l.next;
l.next = l2;
l2 = temp;
}
return l1;
}
}
我们的 while 循环每次比较 p1 和 p2 的大小,把较小的节点接到结果链表上
这个算法的逻辑类似于「拉拉链」,l1, l2 类似于拉链两侧的锯齿,指针 p 就好像拉链的拉索,将两个有序链表合并。
/**
* Definition for singly-linked list.
* public class ListNode {
* int val;
* ListNode next;
* ListNode() {}
* ListNode(int val) { this.val = val; }
* ListNode(int val, ListNode next) { this.val = val; this.next = next; }
* }
*/
class Solution {
public ListNode mergeTwoLists(ListNode l1, ListNode l2) {
ListNode placeHolder = new ListNode(-1);
ListNode p = placeHolder;
ListNode p1 = l1;
ListNode p2 = l2;
while(p1 !=null && p2 != null){
if(p1.val >= p2.val){
p.next = p2;
p2 = p2.next;
}else{
p.next = p1;
p1 = p1.next;
}
p = p.next;
}
if(p1 != null){
p.next = p1;
}
if(p2 !=null){
p.next = p2;
}
return placeHolder.next;
}
}
可以使用PlaceHolder占位符,否则返回它的下一个节点,否则返回链表的下一个节点需要在循环前判断给出,会多出很多代码。
再来看一道相似解法的题目

/**
* Definition for singly-linked list.
* public class ListNode {
* int val;
* ListNode next;
* ListNode() {}
* ListNode(int val) { this.val = val; }
* ListNode(int val, ListNode next) { this.val = val; this.next = next; }
* }
*/
class Solution {
int[] array;
int shouldBreak=0;
public ListNode mergeKLists(ListNode[] lists) {
ListNode PlaceHolder = new ListNode(-1);
ListNode p = PlaceHolder;
//特殊情况判断
if(lists.length == 0) return PlaceHolder.next;
array = new int[lists.length];
for(int i=0;i<array.length;i++){
array[i] = Integer.MAX_VALUE;
}
while(true){
if(shouldBreak == 1) break;
for(int i=0;i<lists.length;i++){
if(lists[i] != null) array[i] = lists[i].val;
else array[i] = Integer.MAX_VALUE;
}
int listPosition = getMinFromK(array);
//可能出现array数组中全部都是 Integer.MAX_VALUE的情况,比如给的数据是[[],[]],这样的,也可以通过将下面的for循环提前来解决这个w
if(listPosition == -1) break;
p.next = lists[listPosition];
p = p.next;
lists[listPosition] = lists[listPosition].next;
shouldBreak = 1;
for(int i=0;i<lists.length;i++){
if(lists[i] != null)
shouldBreak = 0;
}
}
return PlaceHolder.next;
}
int getMinFromK(int[] array){
int min = array[0];
int curListPosition = 0;
for(int i=1;i<array.length;i++){
if(array[i] < min){
min = array[i];
curListPosition = i;
}
}
return min == Integer.MAX_VALUE?-1:curListPosition;
}
}
快慢指针
快慢指针一般都初始化指向链表的头结点 head,前进时快指针 fast 在前,慢指针 slow 在后,巧妙解决一些链表中的问题。
比如可以让快指针一次走俩步,慢指针一次走一步,快指针一直指到NULL或者快指针所指向的对象的next节点为NULL时就停止运动,此时慢指针就指向链表的中间位置
再比如判断链表中是否有环,如果无环则快指针会指到NULL,快慢指针不会相遇,如果有环,快指针就会在环那里打转转,会和慢指针相遇
boolean hasCycle(ListNode head) {
ListNode fast, slow;
fast = slow = head;
while (fast != null && fast.next != null) {
fast = fast.next.next;
slow = slow.next;
if (fast == slow) return true;
}
return false;
}
再进阶点,如果有环则返回环的第一个节点呢?
public class Solution {
public ListNode detectCycle(ListNode head) {
ListNode fast = head, slow = head;
while (true) {
if (fast == null || fast.next == null) return null;
fast = fast.next.next;
slow = slow.next;
if (fast == slow) break;
}
fast = head;
while (slow != fast) {
slow = slow.next;
fast = fast.next;
}
return fast;
}
}
解释一下,设链表共有 a+b 个节点,其中 链表头部到链表入口 有 a 个节点(不计链表入口节点), 链表环 有 b 个节点,设两指针分别走了 f,s步
俩指针相遇时则有:
f = 2 s 和 f = s + nb 俩式子相减得 s = nb 和 f = 2nb 即慢指针走了n个链表环得长度,快指针走了2n个链表环得长度
而让指针可以到达链表环得总步数是 a+nb 那慢指针再走a步就可以达到链表环得头部
所以让快指针指向头部,此时让快慢指针都同时只走1步,当他们再同时相遇时肯定是在环的头部相遇!
fast = head;
while (slow != fast) {
slow = slow.next;
fast = fast.next;
}
return fast or slow;
最后一个例子寻找链表的倒数第 n 个元素

//注意特殊处理倒数第 n 个节点就是第一个节点的情况
ListNode removeNthFromEnd(ListNode head, int n) {
ListNode fast, slow;
fast = slow = head;
// 快指针先前进 n 步
while (n-- > 0) {
fast = fast.next;
}
if (fast == null) {
// 如果此时快指针走到头了,
// 说明倒数第 n 个节点就是第一个节点
return head.next;
}
// 让慢指针和快指针同步向前
while (fast != null && fast.next != null) {
fast = fast.next;
slow = slow.next;
}
// slow.next 就是倒数第 n 个节点,删除它
slow.next = slow.next.next;
return head;
}
相交链表

/**
* Definition for singly-linked list.
* public class ListNode {
* int val;
* ListNode next;
* ListNode(int x) {
* val = x;
* next = null;
* }
* }
*/
public class Solution {
public ListNode getIntersectionNode(ListNode headA, ListNode headB) {
ListNode head = headB;
while(headA != null){
while(head != null){
if(head == headA){
return headA;
}
head = head.next;
}
headA = headA.next;
head = headB;
}
return null;
}
}
思路 选定一条链表,从头开始,一次移动一个节点,另外一条链表遍历整个链表判断是否有节点和选定链表的节点相同
另外一种解法,让俩条链表逻辑上相邻
/**
* Definition for singly-linked list.
* public class ListNode {
* int val;
* ListNode next;
* ListNode(int x) {
* val = x;
* next = null;
* }
* }
*/
public class Solution {
public ListNode getIntersectionNode(ListNode headA, ListNode headB) {
ListNode p1 = headA, p2 = headB;
while (p1 != p2) {
// p1 走一步,如果走到 A 链表末尾,转到 B 链表
if (p1 == null) p1 = headB;
else p1 = p1.next;
// p2 走一步,如果走到 B 链表末尾,转到 A 链表
if (p2 == null) p2 = headA;
else p2 = p2.next;
}
return p1;
}
}
反转链表

ListNode reverse(ListNode head) {
if (head.next == null) return head;
ListNode last = reverse(head.next);
head.next.next = head;
head.next = null;
return last;
}
进阶:
反转前K个节点
ListNode successor = null; // 后驱节点
// 反转以 head 为起点的 n 个节点,返回新的头结点
ListNode reverseN(ListNode head, int n) {
if (n == 1) {
// 记录第 n + 1 个节点
successor = head.next;
return head;
}
// 以 head.next 为起点,需要反转前 n - 1 个节点
ListNode last = reverseN(head.next, n - 1);
head.next.next = head;
// 让反转之后的 head 节点和后面的节点连起来
head.next = successor;
return last;
}
进阶:
反转链表的一部分
和反转前K个节点思路相似,除了要记录succesor节点外还要记录要反转链表第一个节点的左边那个节点(如果从链表第一个节点开始反转要特殊对待)
/**
* Definition for singly-linked list.
* public class ListNode {
* int val;
* ListNode next;
* ListNode() {}
* ListNode(int val) { this.val = val; }
* ListNode(int val, ListNode next) { this.val = val; this.next = next; }
* }
*/
class Solution {
ListNode first;
ListNode successor;
int left;
public ListNode reverseBetween(ListNode head, int left, int right) {
first = head;
this.left = left;
for(int i=0;i<left-2;i++) first = first.next;
//如果从链表第一个节点开始反转 此时返回的节点不能是head,而是反转链表的最后一个节点
if(left == 1) return reverseN(head,right-left+1);
else reverseN(first.next,right-left+1);
return head;
}
ListNode reverseN(ListNode node,int n){
if(n == 1){
if(left != 1) first.next = node;
successor = node.next;
return node;
}
ListNode lastNode = reverseN(node.next,n-1);
node.next.next = node;
node.next = successor;
return lastNode;
}
}
回文链表
用到了递归后序遍历的思想和双指针
/**
* Definition for singly-linked list.
* public class ListNode {
* int val;
* ListNode next;
* ListNode() {}
* ListNode(int val) { this.val = val; }
* ListNode(int val, ListNode next) { this.val = val; this.next = next; }
* }
*/
class Solution {
boolean res = true;
ListNode left;
public boolean isPalindrome(ListNode head) {
if(head.next == null) return true;
left = head;
ListNode slowNode = head;
ListNode fastNode =head;
while(fastNode!=null && fastNode.next!=null){
slowNode = slowNode.next;
fastNode = fastNode.next.next;
}
if(fastNode != null) slowNode = slowNode.next;
reverseAndCheck(slowNode);
return res;
}
void reverseAndCheck(ListNode node){
if(node == null) return;
reverseAndCheck(node.next);
res = res && (left.val == node.val);
left = left.next;
}
}
二叉树
填充二叉树节点的右侧指针
题目:把二叉树的每一层节点都用 next 指针连接起来:

很容易想到以下代码:
Node connect(Node root) {
//递归结束条件
if (root == null || root.left == null) {
return root;
}
//实际执行代码
root.left.next = root.right;
//递归语句
connect(root.left);
connect(root.right);
return root;
}
按照我们之前讲的 明确函数的「定义」是什么,然后相信这个定义,利用这个定义推导最终结果,这个函数的定义是给定一个节点然后将这个节点的左右节点相连
但这样会有问题:不是同一个父节点的俩个子节点没有办法被连接 如图,即5,6没有办法被连接

因此我们需要改变函数定义
改为给俩个节点,然后连接这俩个节点.
Node connect(Node root) {
if (root == null) return null;
connectTwoNode(root.left, root.right);
return root;
}
void connectTwoNode(Node node1, Node node2) {
if (node1 == null || node2 == null) {
return;
}
// 将传入的两个节点连接
node1.next = node2;
// 连接相同父节点的两个子节点
connectTwoNode(node1.left, node1.right);
connectTwoNode(node2.left, node2.right);
// 连接跨越父节点的两个子节点
connectTwoNode(node1.right, node2.left);
}
将二叉树展开为链表

给出这个函数的定义:
给 flatten 函数输入一个节点 root,那么以 root 为根的二叉树就会被拉平为一条链表。

代码:
// 定义:将以 root 为根的树拉平为链表
void flatten(TreeNode root) {
// base case
if (root == null) return;
flatten(root.left);
flatten(root.right);
/**** 后序遍历位置 ****/
// 1、左右子树已经被拉平成一条链表
TreeNode left = root.left;
TreeNode right = root.right;
// 2、将左子树作为右子树
root.left = null;
root.right = left;
// 3、将原先的右子树接到当前右子树的末端
TreeNode p = root;
while (p.right != null) {
p = p.right;
}
p.right = right;
}
最大二叉树

函数定义题目已经给出,这可以说是怎么写递归函数中最复杂的部分了
/* 主函数 */
TreeNode constructMaximumBinaryTree(int[] nums) {
return build(nums, 0, nums.length - 1);
}
/* 将 nums[lo..hi] 构造成符合条件的树,返回根节点 */
TreeNode build(int[] nums, int lo, int hi) {
// base case
if (lo > hi) {
return null;
}
// 找到数组中的最大值和对应的索引
int index = -1, maxVal = Integer.MIN_VALUE;
for (int i = lo; i <= hi; i++) {
if (maxVal < nums[i]) {
index = i;
maxVal = nums[i];
}
}
TreeNode root = new TreeNode(maxVal);
// 递归调用构造左右子树
root.left = build(nums, lo, index - 1);
root.right = build(nums, index + 1, hi);
return root;
}
通过前序和中序遍历结果构造二叉树

函数签名如下:
TreeNode buildTree(int[] preorder, int[] inorder);
递归函数定义:给前序遍历以及中序遍历的数组得到一个二叉树的头节点并返回
我们写的递归函数在官方给的函数的基础上加上数组下标就好了
我们可以先从前序遍历数组的第一个数得到头节点的值,然后通过这个值去中序遍历数组去找,找到的数的左边的数组是左子树,右边的数组是右子树,这个时候递归语句就找到了
代码:
TreeNode build(int[] preorder, int preStart, int preEnd,
int[] inorder, int inStart, int inEnd) {
if (preStart > preEnd) {
return null;
}
// root 节点对应的值就是前序遍历数组的第一个元素
int rootVal = preorder[preStart];
// rootVal 在中序遍历数组中的索引
int index = 0;
for (int i = inStart; i <= inEnd; i++) {
if (inorder[i] == rootVal) {
index = i;
break;
}
}
//左子树有几个节点
int leftSize = index - inStart;
// 先构造出当前根节点
TreeNode root = new TreeNode(rootVal);
// 递归构造左右子树
root.left = build(preorder, preStart + 1, preStart + leftSize,
inorder, inStart, index - 1);
root.right = build(preorder, preStart + leftSize + 1, preEnd,
inorder, index + 1, inEnd);
return root;
}
通过后序和中序遍历结果构造二叉树

函数签名如下:
TreeNode buildTree(int[] inorder, int[] postorder);
和上道题类似,前序遍历的第一个值是头节点的值,而后序遍历的最后一个值是头节点的值,有个头节点的值我们就可以去中序遍历的数组中去找到头节点,头节点的左边是左子树,而头节点的右边就是右子树,再对这俩颗树进行递归即可
代码:
TreeNode build(int[] inorder, int inStart, int inEnd,
int[] postorder, int postStart, int postEnd) {
if (inStart > inEnd) {
return null;
}
// root 节点对应的值就是后序遍历数组的最后一个元素
int rootVal = postorder[postEnd];
// rootVal 在中序遍历数组中的索引
int index = 0;
for (int i = inStart; i <= inEnd; i++) {
if (inorder[i] == rootVal) {
index = i;
break;
}
}
// 左子树的节点个数
int leftSize = index - inStart;
TreeNode root = new TreeNode(rootVal);
// 递归构造左右子树
root.left = build(inorder, inStart, index - 1,
postorder, postStart, postStart + leftSize - 1);
root.right = build(inorder, index + 1, inEnd,
postorder, postStart + leftSize, postEnd - 1);
return root;
}
寻找第 K 小的元素
BST有一个重要的性质:它的中序遍历结果是升序的。

int kthSmallest(TreeNode root, int k) {
// 利用 BST 的中序遍历特性
traverse(root, k);
return res;
}
// 记录结果
int res = 0;
// 记录当前元素的排名
int rank = 0;
void traverse(TreeNode root, int k) {
if (root == null) {
return;
}
traverse(root.left, k);
/* 中序遍历代码位置 */
rank++;
if (k == rank) {
// 找到第 k 小的元素
res = root.val;
return;
}
/*****************/
traverse(root.right, k);
}
BST 转化累加树

不能通过每个节点都去计算右子树的和来得到正确的值,因为节点的父节点的值也有可能大于当前节点的值
BST的中序遍历结果是升序的,把中序遍历倒过来即可得到降序的结果
void traverse(TreeNode root) {
if (root == null) return;
// 先递归遍历右子树
traverse(root.right);
// 中序遍历代码位置
print(root.val);
// 后递归遍历左子树
traverse(root.left);
}
维护一个外部累加变量sum,然后把sum赋值给 BST 中的每一个节点,就可以将 BST 转化成累加树
TreeNode convertBST(TreeNode root) {
traverse(root);
return root;
}
// 记录累加和
int sum = 0;
void traverse(TreeNode root) {
if (root == null) {
return;
}
traverse(root.right);
// 维护累加和
sum += root.val;
// 将 BST 转化成累加树
root.val = sum;
traverse(root.left);
}
判断 BST 的合法性
很容易首先想到以下算法:
boolean isValidBST(TreeNode root) {
if (root == null) return true;
if (root.left != null && root.val <= root.left.val)
return false;
if (root.right != null && root.val >= root.right.val)
return false;
return isValidBST(root.left)
&& isValidBST(root.right);
}
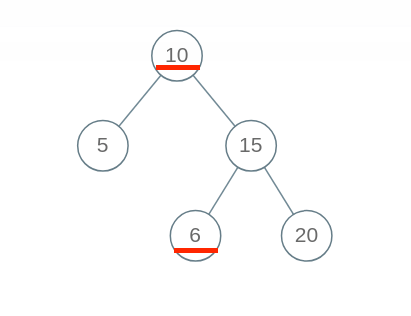
但是这个算法出现了错误,BST 的每个节点应该要小于右边子树的所有节点
出现问题的原因在于,对于每一个节点 root,代码值检查了它的左右孩子节点是否符合左小右大的原则;但是根据 BST 的定义,root 的整个左子树都要小于 root.val,整个右子树都要大于 root.val。 问题是,对于某一个节点 root,他只能管得了自己的左右子节点,怎么把 root 的约束传递给左右子树呢?
其实这里我们的函数定义错了,我们将函数定义为了给定一个节点,判断是否左节点值小于这个节点,右节点值大于这个节点,不妨更改一下递归函数定义,给定一个节点,这个节点的左子树的最大值不能大于它本身,它的右子树的最小值不能小于它
boolean isValidBST(TreeNode root) {
return isValidBST(root, null, null);
}
/* 限定以 root 为根的子树节点必须满足 max.val > root.val > min.val */
boolean isValidBST(TreeNode root, TreeNode min, TreeNode max) {
// base case
if (root == null) return true;
// 若 root.val 不符合 max 和 min 的限制,说明不是合法 BST
if (min != null && root.val <= min.val) return false;
if (max != null && root.val >= max.val) return false;
// 限定左子树的最大值是 root.val,右子树的最小值是 root.val
return isValidBST(root.left, min, root)
&& isValidBST(root.right, root, max);
}
在 BST 中插入一个数
函数定义:给定一个根节点返回一个已经插入了值的树
TreeNode insertIntoBST(TreeNode root, int val) {
// 找到空位置插入新节点
if (root == null) return new TreeNode(val);
if (root.val < val)
//这里的root.right 和root.left要理解为root的左右子树 而不是左右节点
root.right = insertIntoBST(root.right, val);
if (root.val > val)
root.left = insertIntoBST(root.left, val);
return root;
}
在 BST 中删除一个数
分为三种情况



针对第三种情况,A 有两个子节点,为了不破坏 BST 的性质,A 必须找到左子树中最大的那个节点,或者右子树中最小的那个节点来接替自己
函数定义:
给定一个节点和一个值,返回以这个节点为开始的删除了这个值的节点的一颗树
TreeNode deleteNode(TreeNode root, int key) {
if (root == null) return null;
if (root.val == key) {
if (root.left == null) return root.right;
if (root.right == null) return root.left;
TreeNode minNode = getMin(root.right);
root.val = minNode.val;
root.right = deleteNode(root.right, minNode.val);
} else if (root.val > key) {
root.left = deleteNode(root.left, key);
} else if (root.val < key) {
root.right = deleteNode(root.right, key);
}
return root;
}
TreeNode getMin(TreeNode node) {
// BST 最左边的就是最小的
while (node.left != null) node = node.left;
return node;
}
不同的二叉搜索树
给你输入一个正整数 n,请你计算,存储 {1,2,3...,n} 这些值共有有多少种不同的 BST 结构。
函数签名如下:
int numTrees(int n);
比如说输入 n = 3,算法返回 5,因为共有如下 5 种不同的 BST 结构存储 {1,2,3}:

定义函数
// 定义:闭区间 [lo, hi] 的数字能组成 count(lo, hi) 种 BST
int count(int lo, int hi);
/* 主函数 */
int numTrees(int n) {
// 计算闭区间 [1, n] 组成的 BST 个数
return count(1, n);
}
/* 计算闭区间 [lo, hi] 组成的 BST 个数 */
int count(int lo, int hi) {
// base case
if (lo > hi) return 1;
int res = 0;
for (int i = lo; i <= hi; i++) {
// i 的值作为根节点 root
int left = count(lo, i - 1);
int right = count(i + 1, hi);
// 左右子树的组合数乘积是 BST 的总数
res += left * right;
}
return res;
}
时间复杂度高,使用备忘录:
// 备忘录
int[][] memo;
int numTrees(int n) {
// 备忘录的值初始化为 0
memo = new int[n + 1][n + 1];
return count(1, n);
}
int count(int lo, int hi) {
if (lo > hi) return 1;
// 查备忘录
if (memo[lo][hi] != 0) {
return memo[lo][hi];
}
int res = 0;
for (int mid = lo; mid <= hi; mid++) {
int left = count(lo, mid - 1);
int right = count(mid + 1, hi);
res += left * right;
}
// 将结果存入备忘录
memo[lo][hi] = res;
return res;
}
二叉树的序列化
前序遍历序列化:
String SEP = ",";
String NULL = "#";
/* 主函数,将二叉树序列化为字符串 */
String serialize(TreeNode root) {
StringBuilder sb = new StringBuilder();
serialize(root, sb);
return sb.toString();
}
/* 辅助函数,将二叉树存入 StringBuilder */
void serialize(TreeNode root, StringBuilder sb) {
if (root == null) {
sb.append(NULL).append(SEP);
return;
}
/****** 前序遍历位置 ******/
sb.append(root.val).append(SEP);
/***********************/
serialize(root.left, sb);
serialize(root.right, sb);
}
前序遍历反序列化:
/* 主函数,将字符串反序列化为二叉树结构 */
TreeNode deserialize(String data) {
// 将字符串转化成列表
LinkedList<String> nodes = new LinkedList<>();
for (String s : data.split(SEP)) {
nodes.addLast(s);
}
return deserialize(nodes);
}
/* 辅助函数,通过 nodes 列表构造二叉树 */
TreeNode deserialize(LinkedList<String> nodes) {
if (nodes.isEmpty()) return null;
/****** 前序遍历位置 ******/
// 列表最左侧就是根节点
String first = nodes.removeFirst();
if (first.equals(NULL)) return null;
TreeNode root = new TreeNode(Integer.parseInt(first));
/***********************/
//这里一直在疑惑它这里直接将整个nodes穿过了,难道不会出现root.left = deserialize(nodes);这行代码把本来属于右子树的数据拿走的情况吗?后来仔细思考应该是NULL字符起到了阻隔的效果,但是它是怎么起作用的呢?在序列化过程中,我们前序遍历二叉树会首先操作root,然后递归它的左右子树并进行操作,假如有一个root节点,它有一个左节点和一个右节点,且左节点和右节点都没有子节点了,我们序列化时首先将root加入,然后加入root左节点的值,然后加入NULL NULL,最后加入右节点...... 最后结果就是 root root.left NULL NULL root.right NULL NULL 那我们在反序列时就能通过这个NULL来起到阻隔的效果
root.left = deserialize(nodes);
root.right = deserialize(nodes);
return root;
}
数组
左右指针
俩数之和

让一个指针指向数组最左边,一个指针指向数组最右边,因为数组升序排列所以左指针向左移动左右指针之和会增大,右指针向左移动左右指针之和会减小。
int[] twoSum(int[] nums, int target) {
int left = 0, right = nums.length - 1;
while (left < right) {
int sum = nums[left] + nums[right];
if (sum == target) {
// 题目要求的索引是从 1 开始的
return new int[]{left + 1, right + 1};
} else if (sum < target) {
left++; // 让 sum 大一点
} else if (sum > target) {
right--; // 让 sum 小一点
}
}
return new int[]{-1, -1};
}
反转数组
val arr = intArrayOf(1, 2, 3, 4, 5)
var left = 0
var right = arr.size - 1
while (left < right) {
//俩种很有意思的不用中间数交换数值的方法
// arr[left] = arr[left] + arr[right]
// arr[right] = arr[left] - arr[right]
// arr[left] = arr[left] - arr[right]
arr[left] = arr[left] xor arr[right]
arr[right] = arr[right] xor arr[left]
arr[left] = arr[left] xor arr[right]
left += 1
right -= 1
}
for ((index, value) in arr.withIndex()) {
println(arr[index])
}
滑动窗口
框架代码:
/* 滑动窗口算法框架 */
void slidingWindow(string s, string t) {
unordered_map<char, int> need, window;
for (char c : t) need[c]++;
int left = 0, right = 0;
int valid = 0;
while (right < s.size()) {
// c 是将移入窗口的字符
char c = s[right];
// 右移窗口
right++;
// 进行窗口内数据的一系列更新
...
/*** debug 输出的位置 ***/
printf("window: [%d, %d)\n", left, right);
/********************/
// 判断左侧窗口是否要收缩
while (window needs shrink) {
// d 是将移出窗口的字符
char d = s[left];
// 左移窗口
left++;
// 进行窗口内数据的一系列更新
...
}
}
}
其中两处 ... 表示的更新窗口数据的地方
用框架写的leetcode76题
string minWindow(string s, string t) {
unordered_map<char, int> need, window;
for (char c : t) need[c]++;
int left = 0, right = 0;
int valid = 0;
// 记录最小覆盖子串的起始索引及长度
int start = 0, len = INT_MAX;
while (right < s.size()) {
// c 是将移入窗口的字符
char c = s[right];
// 右移窗口
right++;
// 进行窗口内数据的一系列更新
if (need.count(c)) {
window[c]++;
if (window[c] == need[c])
valid++;
}
// 判断左侧窗口是否要收缩
while (valid == need.size()) {
// 在这里更新最小覆盖子串
if (right - left < len) {
start = left;
len = right - left;
}
// d 是将移出窗口的字符
char d = s[left];
// 左移窗口
left++;
// 进行窗口内数据的一系列更新
if (need.count(d)) {
if (window[d] == need[d])
valid--;
window[d]--;
}
}
}
// 返回最小覆盖子串
return len == INT_MAX ?
"" : s.substr(start, len);
}

滑动窗口算法的思路是这样:
1、我们在字符串 S 中使用双指针中的左右指针技巧,初始化 left = right = 0,把索引左闭右开区间 [left, right) 称为一个「窗口」。
2、我们先不断地增加 right 指针扩大窗口 [left, right),直到窗口中的字符串符合要求(包含了 T 中的所有字符)。
3、此时,我们停止增加 right,转而不断增加 left 指针缩小窗口 [left, right),直到窗口中的字符串不再符合要求(不包含 T 中的所有字符了)。同时,每次增加 left,我们都要更新一轮结果。
4、重复第 2 和第 3 步,直到 right 到达字符串 S 的尽头。
第 2 步相当于在寻找一个「可行解」,然后第 3 步在优化这个「可行解」,最终找到最优解
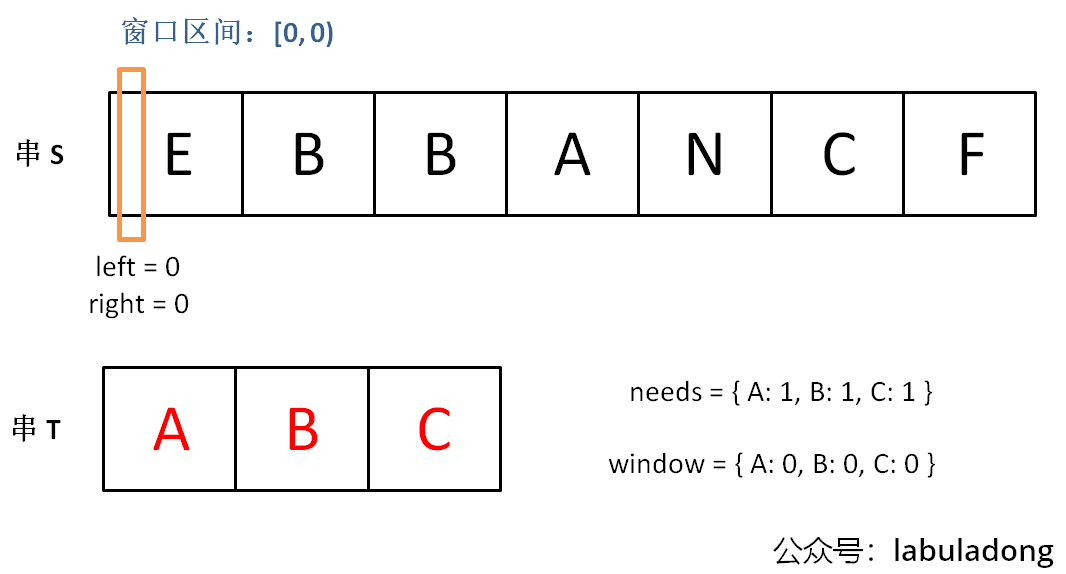
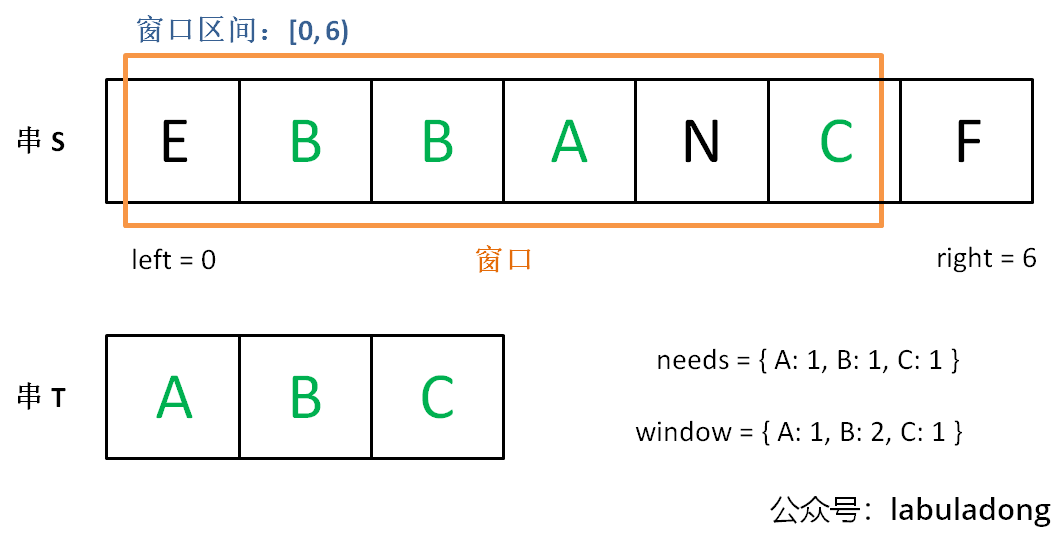
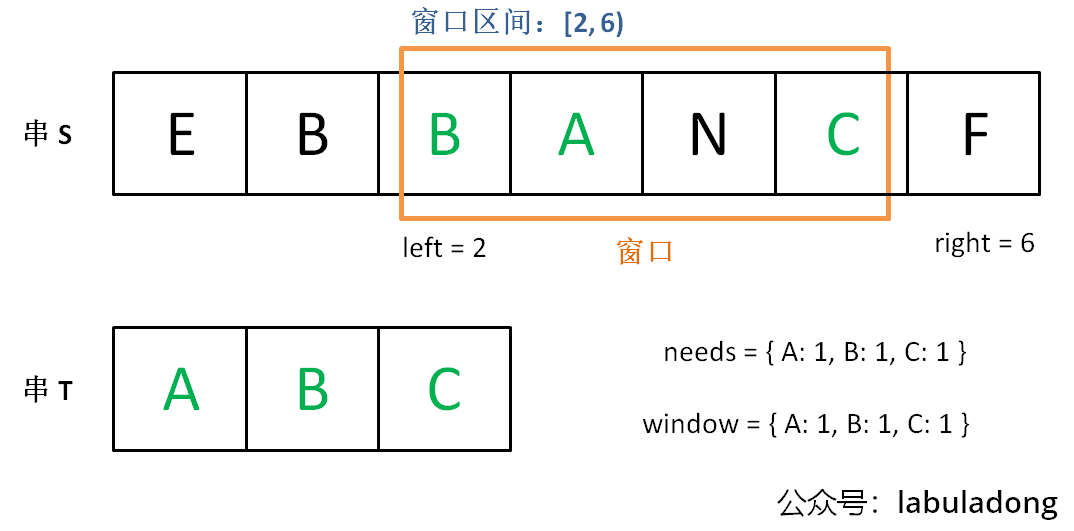
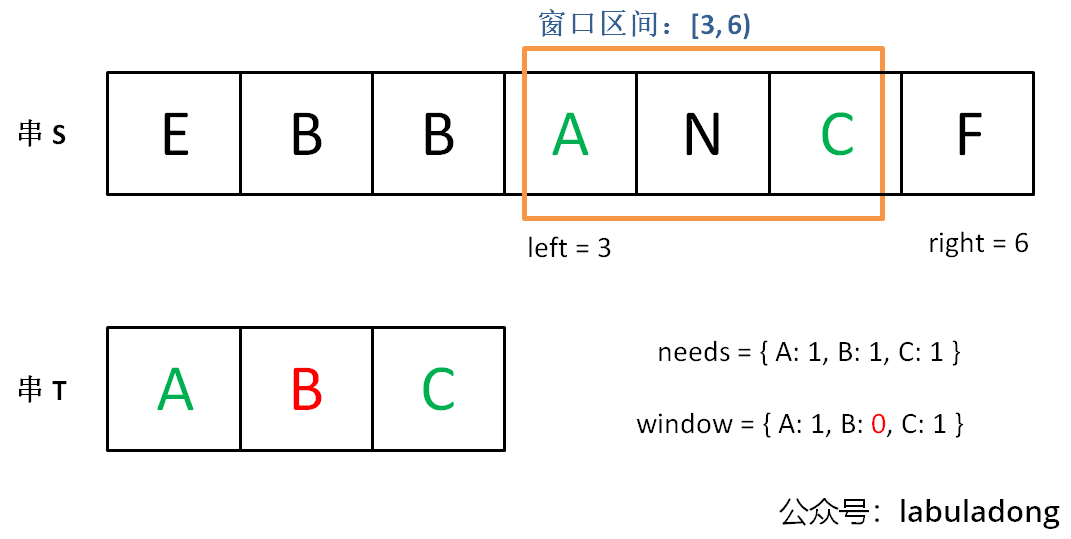
来思考一下我们应该怎么解决滑动窗口的题
首先我们需要一个map用来当作窗口然后移动窗口得右边界(最多移动到所有值得最右边),每移动一次检查是否还要继续扩大窗口并更新数据,如果需要缩小窗口了 就缩小窗口,每缩小一次更新数据并判断是否还要接着缩小窗口
原地修改数组,避免数据的搬移(双指针)

函数签名如下:
int removeDuplicates(int[] nums);
这道题虽然title是删除排序数组的重复项,但它的返回值只要求返回新数组的长度,所以其实我们不必真的删除某个元素,而是得到非重复数字的个数
利用这是一个排序数组的特性,则所有相同的元素都会相邻的特性
我们可以使用快慢指针,先让快慢指针同时指在第一个节点,然后让快指针在前面“探路”,慢指针不动,快指针指到和慢指针不同的元素时,就让慢指针前进一步并将慢指针所指向的值改为快指针所指向的值,这样就能保证nums[0..slow] 无重复,最后无重复数字的个数就是slow+1
int removeDuplicates(int[] nums) {
if (nums.length == 0) {
return 0;
}
int slow = 0, fast = 0;
while (fast < nums.length) {
if (nums[fast] != nums[slow]) {
slow++;
// 维护 nums[0..slow] 无重复
nums[slow] = nums[fast];
}
fast++;
}
// 数组长度为索引 + 1
return slow + 1;
}
设计数据结构
数据流的中位数

本题的核心思路是使用两个优先级队列。
我们可以把「有序数组」抽象成一个倒三角形,宽度可以视为元素的大小,那么这个倒三角的中部就是计算中位数的元素:

然后我把这个大的倒三角形从正中间切成两半,变成一个小倒三角和一个梯形,这个小倒三角形用大顶堆来实现,这个梯形用小顶堆来实现。
则可以写出以下的找中位数的代码
class MedianFinder {
private PriorityQueue<Integer> large;
private PriorityQueue<Integer> small;
public MedianFinder() {
// 小顶堆
large = new PriorityQueue<>();
// 大顶堆
small = new PriorityQueue<>((a, b) -> {
return b - a;
});
}
public double findMedian() {
// 如果元素不一样多,多的那个堆的堆顶元素就是中位数
if (large.size() < small.size()) {
return small.peek();
} else if (large.size() > small.size()) {
return large.peek();
}
// 如果元素一样多,两个堆堆顶元素的平均数是中位数
return (large.peek() + small.peek()) / 2.0;
}
public void addNum(int num) {
if (small.size() >= large.size()) {
small.offer(num);
large.offer(small.poll());
} else {
large.offer(num);
small.offer(large.poll());
}
}
}
加元素不可以这样实现:
每次调用addNum函数的时候,我们比较一下large和small的元素个数,谁的元素少我们就加到谁那里,如果它们的元素一样多,我们默认加到large里面
因为我们要保持Large优先队列中最小的元素大于等与Small优先队列中最大的元素
想要往large里添加元素,不能直接添加,而是要先往small里添加,然后再把small的堆顶元素加到large中;向small中添加元素同理。